
It's the last day of #blogjune!
We hope you've enjoyed reading through the posts for this year, our regular posting schedule will return, starting next week.
Today's post comes from the blog of Tim Sherratt, who is on the Trove Managment team at the NLA and an Associate Professor of Digital Heritage at the University of Canberra.
You can follow Tim on Twitter @wragge!
Keynote presented at the Annual Conference of the Japanese Association for the Digital Humanities, 20 September 2014, Tsukuba.
The full set of slides is available on SlideShare.
Cross-published on Medium.
--This is Tatsuzo Nakata. In 1913 he was living on Thursday Island in the Torres Strait, just off the northern tip of Australia.

From the late 19th century there was a substantial Japanese population on Thursday Island, mostly associated with the development of the pearling industry.
I’ll admit that I know very little about Tatsuzo, and I’ve selected him more or less at random from a large body of records held by the National Archives of Australia.
I present him here out of context and in too little detail, simply as an example. Working backwards from this photograph I want to restore some layers of context and reveal to you a complex and shameful history.
This photograph was attached to an official government form called a ‘Certificate Exempting From Dictation Test’.
From the form we learn that the 32 year-old Tatsuzo was born in Wakayama. He had a scar over his right eye.

Tatsuzo carried a copy of this form with him when he departed for Japan aboard the Yawata Maru in May 1913. When he returned the following year the form was collected and compared with a duplicate held by port officials. The forms matched, and Tatsuzo was allowed to disembark.
To help confirm his identity, the form carried on its reverse side an impression of Tatsuzo’s hand.
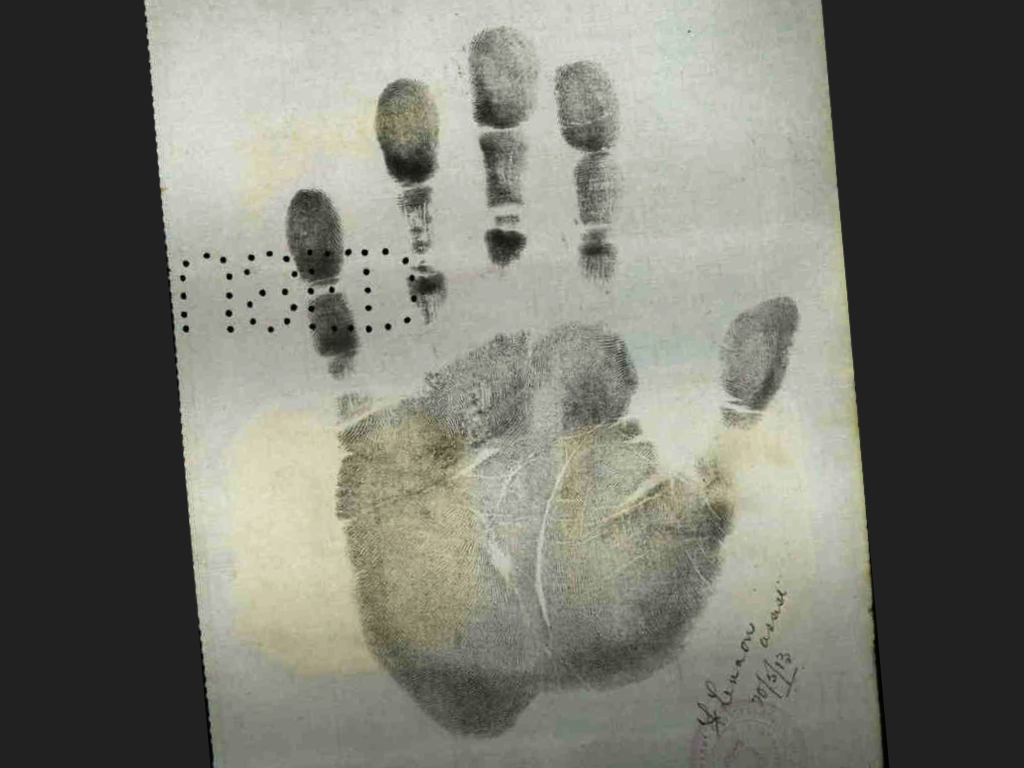
You might think that this was a travel document — an early form of visa perhaps. But at the top of the form you’ll notice a reference to the Immigration Restriction Act, a piece of legislation introduced by the newly-federated Australian nation in 1901. The Immigration Restriction Act and the complex bureaucratic procedures that supported its administration came to be known more generally as the White Australia Policy.
If Tatsuzo had tried to return to Australia without one of these forms, he would have been subjected to the Dictation Test, and he would have failed. Despite its benign-sounding name, the Dictation Test was a form of racial exclusion aimed at anyone deemed non-white. No-one was meant to pass. If he hadn’t carried this form exempting him from the Dictation Test, Tatsuzo would most likely have been denied re-entry.
This certificate is drawn from one of more than 14,000 files inSeries J2483 in the National Archives of Australia. This series is solely concerned with the administration of the White Australia Policy. There are many other series from other ports and other time periods full of documents like this. The National Archives holds many, many thousands of these certificates documenting the lives and movements of people considered out of place in a White Australia.
Photographs, forms, files, series, legislation — this small shard of Tatsuzo’s life is preserved as part of a racist system of exclusion and control. But what happens when we extract the photos from their context within the recordkeeping system and simply present them as people?
I’ve created a site where you can explore some of the records relating to Japanese people held in Series J2483. Instead of navigating lists of files, you can start with faces — with the people, not the system.

Shark Attack!
After a series of fatal shark attacks in Australian waters, the community of Port Hacking, in southern Sydney, began to wonder if they too were at risk.
In January 2014 the local newspaper published an article under the heading ‘Shark “cover up” in Port Hacking’ alleging that research into the dangers had been suppressed.
Ten days later the newspaper followed up with details of the area’s only recorded fatal shark attack in 1927. A local government member, it reported, had ‘unearthed the article on Trove’.
‘It’s long been a story that a boy was killed by a shark at Grays Point many years ago’, he said, ‘I knew about it 30 to 40 years ago but if you talk to people around here, nobody knows about it’.
‘A lot of people say there are no sharks in Port Hacking but this is rubbish’, he added.
Let me reassure anyone thinking about coming to DH2015 in Sydney next year that shark attacks are extremely rare.
What interested me about these articles was not the risk of gruesome death, but the relationship between past and present. The question of whether shark attacks were possible could be answered — simply by searching Trove.
Trove
For those who don’t know, Trove is a discovery service developed and maintained by the National Library of Australia. LikeEuropeana, the Digital Public Library of America, and DigitalNZ, it aggregates resources from the cultural heritage sector, and beyond.
It also provides access to more than 130 million newspaper articlesfrom 1803 onwards. The articles are drawn from over 600 different titles — large and small, rural and metropolitan — with more are being added all the time.
Search for just about anything and you’re likely to find a match of some sort amongst the digitised newspapers. So of course I searched for Tsukuba…

Trove is also a community. Users correct the OCR’d text of newspaper articles. They also add
thousands of tags and comments to resources across Trove.
Perhaps my favourite example of user-generated content on Trove are the Lists. Lists are pretty much what they sound like — collections of resources. They make it easy for you to save and share your research. But more than tags or comments they expose people’s interests and passions. They give some insight into the many acts of meaning-making that occur in and around Trove.
Lists are also exposed through Trove’s Application Programming Interface (API) in a form fit for machine consumption. So with just a dash of code I can harvest the titles of all public lists and do some very basic word frequency analysis courtesy of Voyant Tools.

There’s nothing too surprising here — we know that family historians are our largest user group. But we can also see the long tail in action — the way that huge collections like Trove can support very focused, specific interests.
Which leads me back to shark attacks.
Old Speak
The Port Hacking article made me wonder how many other web pages there might be out on the wider web that cited Trove newspapers in a discussion of shark attacks. The answer was many. But what was most interesting wasn’t the volume of references, it was the variety of contexts — in blog posts, on Facebook, in fishing forums.
‘Ahh, old time newspapers are fascinating things aren’t they?’, notes one post in a weather forum, citing details of a shark attack in Sydney from 1952.
On a fishing site, a thread on bull shark attacks in Western Australia’s Swan River begins: ‘I found a great website to view really old newspapers in perth. Just found a few swan river shark storys [sic]…’.
The author follows up with a direct link to the Trove search page, prompting the exchange:
Redfin 4 Life: ‘Haha you would never know there had been that many incedents in the swan without seeing these…’Goodz: ‘Oh how newspapers have changed the way the write… love the old speak!’Alan James: ‘That’s right Goodz, and more often than not I’m sure they actually reported the truth.’
So a discussion of shark attacks turns to a consideration of the changing style of newspaper reporting.
Perhaps even more interesting is the way that digitised newspapers are used to test a hypothesis, challenge an interpretation, or argue a case. As in the Port Hacking case, questions about the history of shark attacks can be explored without needing to turn to experts, history books, or official statistics.
So when a local politician is quoted as saying ‘there have not been any serious or fatal shark attacks at Coogee Beach since records commenced in the 1800s’, a reader can respond with two Trove newspaper citations and the comment: ‘No previous shark attacks? Or are they only searching for fatalities?’
When a media outlet asks its Facebook followers whether the export of live sheep from Western Australia might be increasing the number of shark attacks off the coast, one follower can simply share a Trove link to a newspaper article from 1950 and ask ‘Did they have live sheep export in 1950?’
I don’t want to argue that these interactions are particularly profound or remarkable. In fact I’d suggest that they’re interesting because they’re not remarkable. 130 million digitised newspaper articles chronicling 150 years of Australian history are just another resource woven into the fabric of online experience. The past can be mobilised, shared and embedded in our daily interactions as easily as pictures of cats.
Traces
And it’s not just shark attacks. To explore the variety of contexts in which Trove newspaper articles are used and shared, I started mining backlinks.
Backlinks, as the name suggests, are just links out there on the wild, wild web that point back to your site. You can find them in your referrer logs, in Google’s webmaster tools, or simply by searching. I started with a ‘try before you buy’ sample of backlinks from an SEO service.
From there I wrote a script to harvest the linking pages, remove duplicates, extract the newspaper references, retrieve the article details from the Trove API, and save everything to a database for easy exploration. You can play with the results online.

I ended up harvesting 3116 pages from 1780 domains containing 13,389 links to 11,242 articles in Trove. Remember that’s just a sample of all the links to Trove newspapers out there on the web.
What was more surprising than the raw numbers was the diversity of content across those pages. I knew that family and local historians were busily blogging about their Trove discoveries, but I didn’t know that Trove newspapers were being cited in discussions about politics, science, war, sport, music — just about any topic you could imagine.
Nor are these discussions just about Australia. A little quick and dirty analysis suggests that more than 30 languages are represented across those 3000 pages.

This is a work in progress. I hope to expand my hunt for traces — crawling sites for additional references, mining referrals, and inviting the public to nominate pages for inclusion. By adding a simple API I could make it possible for Trove to include links back to relevant pages, like trackbacks on a blog. I also want to understand more about the scope of the content and the motivations of its authors. What is going on here?
Undoubtedly some of these pages constitute link spam or attempts to game search engines, but most do not. Browsing the database you find many examples of interpretation, persistence, and passion. People around the world have something they want to say, something they want to share, and Trove’s millions of newspaper articles provide them with a readily-accessible source of inspiration and evidence.
It’s clear that those many small acts of meaning-making we can observe in Trove’s activity statistics extend beyond a single site — to a much much wider (and wilder) world.
Scale
One day earlier this year, Trove received more than three times its usual number of visitors.

The culprit was the WTF subreddit — a popular place for sharing the weirdities of the web. Someone posted a link to a Trove newspaper article describing the unfortunate demise of a poodle called Cachi, whose fall from a thirteenth-story balcony in Buenos Aires resulted in the deaths of three passers-by.
As well as causing a dramatic spike in Trove’s visitor stats, the post received more than 3000 votes and attracted 677 comments on reddit. Cachi was a hit.
Trove articles pop up regularly on reddit. The traffic spikes they bring are reminders that however proud we might be of our stats, we are but a tiny corner of the web. There’s something much bigger out there.
Michael Peter Edson has long sought to alert cultural heritage organisations to the challenges of scale. In a recent essay he described the web’s ‘dark matter':
There’s just an enormous, humongous, gigantic audience out there connected to the Internet that is starving for authenticity, ideas, and meaning. We’re so accustomed to the scale of attention that we get from visitation to bricks-and-mortar buildings that it’s difficult to understand how big the Internet is—and how much attention, curiosity, and creativity a couple of billion people can have.
Libraries, archives and museums, he argues, need to meet the public where they are, to recognise that vigorous sites of meaning-making are scattered across the vast terrain of the web. Trove newspaper traces and reddit spikes are mere glimpses of the ‘dark matter’ of cultural activity that lurks beneath the apps, the stats, and the corporate hype.
People are already using our digital stuff in ways we don’t expect. The question is whether libraries, archives and museums see this hunger for connection as an invitation or a threat. Do we join the party, or call the police to complain about the noise?
Sharing
There’s something fundamentally human about sharing. Yes, it’s easy to mock the shallowness of a Facebook ‘Like'; to see our obsession with followers, friends and retweets as evidence of our dwindling capacity for attention — reducing engagement and understanding to a single click. But haven’t we always shared — through stories, gossip, jokes, performances, and rituals? Rather than being measured against a threshold of meaning, surely each act of sharing exists on a continuum from the flippant to the philosophical. Just because the act of sharing has been commodified by large social media services seeking to mine our preferences for profit, doesn’t mean it lacks deeper human significance.
A retweet can represent a fleeting interest, a brief moment of distraction. But it can also mark the start of a journey.
Cultural heritage institutions around the world have begun to recognise that sharing is not just a marketing strategy, it’s a mission. As Merete Sanderhoff notes in her foreword to the anthology Sharing is Caring:
When cultural heritage is digital, open and shareable, it becomes common property, something that is right at hand every day. It becomes a part of us.
Aggregation services, like Trove, the Digital Public Library of America, Europeana, and DigitalNZ, bring resources together to share them more easily with the world. Aggregation is only worthwhile if it serves discovery and reuse — it’s a process of mobilisation, rather than collection. As Europeana argues in their 2020 strategy:
We believe culture is a catalyst for social and economic change. But that’s only possible if it’s readily usable and easily accessible for people to build with, build on and share.
Of course the hard part is understanding what makes something ‘readily usable and easily accessible’. What balance do we need between push and pull? Between ease-of-use and technical power? Between licensing and liberty? Between context and creativity?
Busy Bots
The Mechanical Curator was born in the British Library Labs as part of their innovative digital scholarship program. In September 2013, she started posting to Tumblr random images automatically extracted from a collection of 65,000 digitised 19th century books.
It was, Ben O’Steen explained, an experiment in ‘providingundirected engagement with the British Library’s digital content’. The book illustrations moved from inside to outside, opening opportunities for discovery beyond the covers.
But that was just the beginning. A few months later the Mechanical Curator dramatically expanded its labours, uploading more than a million public domain images to Flickr.
What followed was something of a cultural feeding frenzy as people from all over the world starting sharing, tagging, collecting, and creating with this rich assortment of 19th century illustrations. Since then the images have been mashed up into new works, added and organised in the Wikimedia Commons, and featured in aninstallation at the Burning Man festival in Nevada.

Having been locked away within books for more than a hundred years, the illustrations were given new life online as works in their own right. Opportunities for innovation and expression were created by a rupture in context.
Meanwhile on Twitter, a growing army of bots was liberating items from cultural collections around the world. Inspired by the bot-making genius of Mark Sample, I created @TroveNewsBot in June 2013 to tweet newspaper articles from Trove.
He was joined by @DPLABot, @EuropeanaBot, @Kasparbot,@CurtinLibBot, @DigitalNZ.bot, @museumbot,@cooperhewittbot, @bklynmuseumbot, and no doubt others — all sharing random collection items. Of course @MechCuratorBotsoon joined the fray from the British Library, and I eventually added @Trovebot to tweet material from all the non-newspapery sections of Trove.
The possibilities of serendipitous discovery are receiving increasing attention within the digital humanities. At DH2014, Kim Martin and Anabel Quan-Haase critically examined four DH tools — including @TroveNewsBot — in the light of existing models of serendipity. Their discussion noted that randomness is not the same as serendipity, and outlined how serendipity could be understood as type of encounter with information. I do wonder though if what makes the bots interesting is not randomness as such, but the way randomness can play around with our assumptions about context.
Steve Lubar observes that the random offerings of collection bots can also expose the choices that are made in the creation and display of cultural collections. Randomness can challenge our expectations. Describing the genesis of the Mechanical Curator,James Baker notes:
And so as what at first seemed simple descends into complexity the Mechanical Curator achieves her peculiar aim: giving knowledge with one hand, carpet bombing the foundations of that knowledge with the other.
The Trove bots I created do more than tweet random offerings, they also allow you to interact with Trove without ever leaving Twitter. Send a few keywords their way and they’ll do your searching for you, tweeting back the most relevant result. You can modify their default behaviour by adding a series of hashtags — #luckydip, for example, will spice your result with a touch of randomness.
More interestingly, perhaps, you can tweet a url at them and they’ll extract keywords from the web page and use them to construct the search. This means that @TroveNewsBot can offer commentary on current events.
Several times a day he retrieves the latest headlines from a news site and searches for something similar amidst Trove’s 130 million historical newspaper articles. What emerges is a strange conversation between past and present.
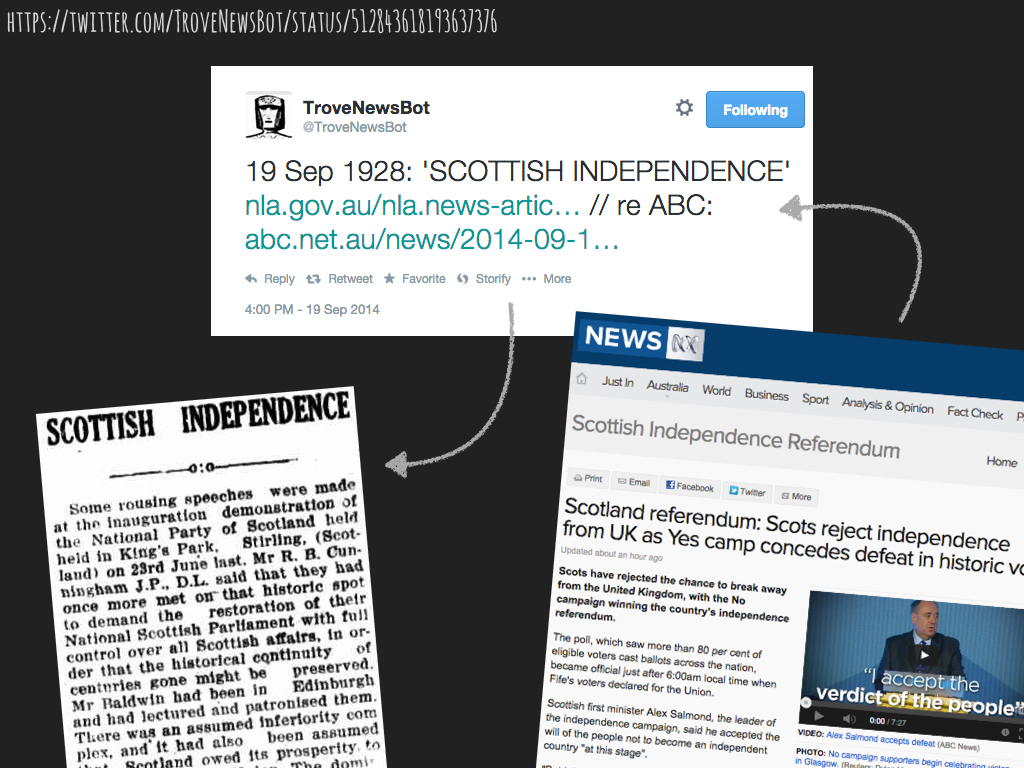
These bots do not simply present collection items outside of the familiar context of discovery interfaces or online exhibitions, they move the encounter itself into a wholly new space. Just as the Mechanical Curator liberates illustrations from the printed page, the Twitter bots loosen the institutional context of collections to allow them to participate in a space where people already congregate. They send collection items out into the wilds of the web, to find new meanings, new connections and perhaps even new love.
Broken & Repaired
But letting go can be scary. A 2008 survey of libraries, archives and museums revealed that one of the main factors inhibiting the opening up of online collections was the desire to avoid misrepresentation, mislabeling or misuse of cultural objects. Easy sharing brings the risk that our carefully curated content will be shorn of context and bounced around the web — adrift and abused.
Earlier this year Sarah Werner took aim at Twitter feeds that pump out streams of ‘historical’ photos — unattributed and often wrongly captioned. But it wasn’t simply the lack of attribution that angered her:
These accounts capitalize on a notion that history is nothing more than superficial glimpses of some vaguely defined time before ours, one that exists for us to look at and exclaim over and move on from without worrying about what it means and whether it happened.
I have to admit that the excitement of seeing Trove’s visitor numbers suddenly soar thanks to reddit is frequently tempered by the realisation that what is being shared is yet another story of gruesome death, violence, or misfortune. 150 years of Australian history is reduced to clickbait by our tabloid sensibilities. Most of those who arrive from reddit read the article and click away — the bounce rate is around 97%. This is not ‘engagement’?
And yet, I can’t help but wonder about the 3% who don’t immediately leave, who pause and look around. Three percent of a lot is still a lot — a lot of people who might have been exposed to Trove and Australian history for the very first time. Similarly while the viral pics industry is frustrating and exploitative, it might yet offer opportunities to learn.
One of my favourite Twitter accounts is @PicsPedant. It monitors many of the viral pics feeds, researches the images, and tweets the results — providing a steady stream of attributions, corrections, critiques, and context. Not only do you find out about the images, you pick up research tips, and learn about the cannibalistic tendencies of the pic bots themselves — constantly recycling content from their kin.
@AhistoricalPics offers a different form of education, satirising the whole viral pics genre with its fabricated captions, and pricking at our own inclination to believe.

Freeing collections opens them to misuse, but it also exposes that misuse to analysis and critique. Contexts can be rediscovered as well as lost, restored as well as broken.
Generous signposts
It’s wonderful to see many Trove newspaper articles shared on Twitter. Unfortunately a significant proportion of these come from climate change deniers, who mine the newspapers for freak weather events and past climatic theories, imagining that such reports undermine current research. This is bad science and bad history. Their efforts are also well-represented in my database of web page citations, along with expressions of hatred and prejudice that I’d prefer to stay submerged. It’s depressing, but it seems inevitable that people will do bad things with your stuff.
In a recent post about the DPLA’s metadata licensing arrangements, Dan Cohen suggested we should look beyond technical and legal controls around online use towards social and ethical guidelines:
The cynics, of course, will say that bad actors will do bad things with all that open data. But here’s the thing about the open web: bad actors will do bad things, regardless… The flip side of worries about bad actors is that we underestimate the number of good actors doing the right thing.
Bad people will do bad things, but by asserting a social and ethical framework for the use of digital cultural collections we strengthen the resolve and commitment of those who want to do right.
Already there are examples in the work of the Local Contexts project which is developing a series of licenses and labels to guide use of traditional knowledge and cultural materials. Similarly, Creative Commons Aotearoa New Zealand have been developing an Indigenous Knowledge Notice to educate the public about what constitutes appropriate use.
We should remember too that footnotes have always been at the heart of an ethical pact. The Australian historian Tom Griffiths has described footnotes as ‘honest expressions of vulnerability’ — ‘generous signposts to anyone who wants to retrace the path and test the insights’. This ‘professional paraphernalia’ has, he argues, grown out of a series of ethical questions:
To whom are we responsible – to the people in our stories, to our sources, to our informants, to our readers and audiences, to the integrity of the past itself? How do we pay our respects, allow for dissent, accommodate complexity, distinguish between our voice and those of our characters?1
Such questions remain crucial as we consider the relationship between cultural collections and their online users. If we expect people to erect ‘generous signposts’ we have to make our stuff easy to find and share. If we want them to consider their responsibility to the past we should focus on providing trust, confidence, and support, not permission.
Responsibilities
If my wall of faces seems seems familiar, it might be because a few years ago I created something similar called The Real Face of White Australia.
The two walls use different sets of records, but they were constructed in much the same way: I reverse-engineered the National Archives’ online database, downloaded images of digitised files, and used a facial detection script to identify and extract faces.
The Real Face of White Australia was an experiment, built over the course of a weekend. But its discomfiting power was immediately evident. Where there had been records, there were people — looking at us, challenging us.
My partner Kate Bagnall is a historian of Chinese-Australia and we were working together on a project called Invisible Australians, aimed at liberating the lives of these people from the bureaucracy of the White Australia Policy.
The project was motivated by a strong sense of responsibility — not to the National Archives, not to the records, but to the people themselves.
We often talk about preserving context as if it’s an end in itself; as if context is just a set of attributes to be catalogued and controlled. The exciting, terrifying, wonderful thing about the wild, wild web is how it upsets our notions of relevance and meaning. Historic newspapers can find their way into contemporary debates. Century-old illustrations can be remade as art. Twitter bots can inspire conversations with collections. The people buried inside a recordkeeping system can be brought at last to the surface. Contexts are unstable, shifting. And through that instability we can glimpse other worlds, we can imagine alternatives, we can build something new.
What’s important is not training users to understand the context of our collections, but helping them explore and understand their responsibilities to the pasts those collections represent.
Let’s remove technical barriers, minimise legal restrictions, and trust in the good will of our audiences. Instead of building shrines to our descriptive methodologies, let’s create systems that provide stable shareable anchors, that connect, but don’t constrain.
Contexts will flow and mingle, some will fade and some will burn. Contexts will survive not because we demand it in our terms of service, or embed them in our interfaces, but because they capture something that matters.
The ways we find and use cultural collections will continue to change, but questions about responsibility, value, and meaning will remain.
- Tom Griffiths, ‘History and the creative imagination’, History Australia, Vol. 6, No. 3, 2009. [
]
